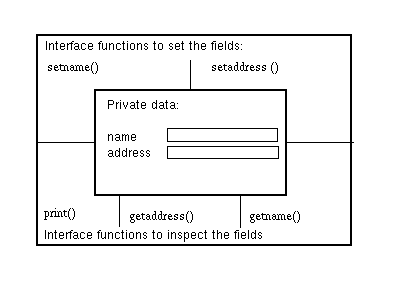
figure 2: Private data and public interface functions of the class Person.
We're always interested in getting feedback. E-mail us if you like this guide, if you think that important material is omitted, if you encounter errors in the code examples or in the documentation, if you find any typos, or generally just if you feel like e-mailing. Mail to Frank Brokken or use an e-mail form. Please state the concerned document version, found in the title. If you're interested in a printable PostScript copy, pick up your own copy inzip-format byftpfrom ftp.icce.rug.nl/pub/http.
In this chapter the usage of C++ is further explored. The possibility to
declare functions in structs is further illustrated using examples. The
concept of a class is introduced.
:: is described first. This operator can be
used in situations where a global variable exists with the same name as a
local variable:
#include <stdio.h>
int
counter = 50; // global variable
int main()
{
for (register int counter = 1; // this refers to the
counter < 10; // local variable
counter++)
{
printf("%d\n",
::counter // global variable
/ // divided by
counter); // local variable
}
return (0);
}
In this code fragment the scope operator is used to address a global variable
instead of the local variable with the same name. The usage of the scope
operator is more extensive than just this, but the other purposes will be
described later.
cout, analogous to stdout,
cin, analogous to stdin,
cerr, analogous to stderr.
Syntactically these streams are not used with functions: instead, data are
read from the streams or written to them using the operators <<, called
the insertion operator and >>, called the extraction operator.
This is illustrated in the example below:
#include <iostream.h>
void main()
{
int
ival;
char
sval[30];
cout << "Enter a number:" << endl;
cin >> ival;
cout << "And now a string:" << endl;
cin >> sval;
cout << "The number is: " << ival << endl
<< "And the string is: " << sval << endl;
}
This program reads a number and a string from the cin stream (usually the
keyboard) and prints these data to cout. Concerning the streams and their
usage we remark the following:
iostream.h.
cout, cin and cerr are in fact `objects'
of a given class (more on classes later), processing the input and
output of a program. Note that the term `object', as used here, means the
set of data and functions which defines the item in question.
cin reads data and copies the information to
variables (e.g., ival in the above example) using the extraction
operator >>. We will describe later how operators in C++
can perform quite different actions than what they are defined to do by the
language grammar, such as is the case here. We've seen function
overloading. In C++ operators can also have multiple
definitions, which is called operator overloading.
cin, cout and cerr
(i.e., >> and <<) also manipulate variables of
different types. In the above example cout << ival results in the
printing of an integer value, whereas cout << "Enter a number"
results in the printing of a string. The actions of the operators
therefore depend on the type of supplied variables.
cout is realized by inserting the
endl symbol, rather than using the string "\n".
The streams cin, cout and cerr are not part of C++ grammar
sec, as defined in the compiler which parses source files. The streams
are part of the definitions in the header file iostream.h. This is
comparable to the fact that functions as printf() are not part of the
C grammar, but were originally written by people who considered such
functions handy and collected them in a run-time library.
Whether a program uses the old-style functions like printf() and
scanf() or whether it employs the new-style streams is a matter of taste.
Both styles can even be mixed. A number of advantages and disadvantages is
given below:
C functions printf() and
scanf(), the usage of the insertion and extraction operators
is more type-safe.
The format strings which are used with printf() and
scanf() can define wrong format specifiers for their arguments,
for which the compiler sometimes can't warn. In contrast, argument
checking with cin, cout and cerr is performed
by the compiler. Consequently it isn't possible to err by providing an
int argument in places where, according to the format string, a string
argument should appear.
printf() and scanf(), and other
functions which use format strings, in fact implement a mini-language
which is interpreted at run-time. In contrast, the C++ compiler
knows exactly which in- or output action to perform given which
argument.
C++.
Again, it requires a little getting used to, coming from C,
but after that these overloaded operators feel rather comfortably.
The iostream library has a lot more to offer than just cin, cout and
cerr. In chapter 9 iostreams will be covered in greater
detail.
void,
char, int, float
and double. C++ extends these five basic types with a two extra
types, the types bool and wchar_t In this section the
type bool is introduced.
The type bool represents boolean (logical) values, for which the
(now reserved) values true and false may be used. Apart from these
reserved values, integral values may also be assigned to variables of type
bool, which are implicitly converted to true and false according
to the following conversion rules (assume intValue is an int-variable,
and boolValue is a bool-variable):
// from int to bool:
boolValue = intValue ? true : false;
// from bool to int:
intValue = boolValue ? 1 : 0;
Furthermore, when bool values are inserted into, e.g., cout, then
1 is written for true values, and 0 is written for false
values. Consider the following example:
cout << "A true value: " << true << endl
<< "A false value: " << false << endl;
The bool data type is found in other programming languages as
well. Pascal has its type Boolean, and Java has a boolean
type. Different from these languages, C++'s type bool acts like a kind
of int type: it's primarily a documentation-improving type, having just two
values true and false. Actually, these values can be interpreted as
enum values for 1 and 0. Doing so would neglect the philosophy
behind the bool data type, but nevertheless: assigning true to an
int variable neither produces warnings nor errors.
Using the bool-type is generally more intuitively clear than using
int. Consider the following prototypes:
bool exists(char const *fileName); // (1)
int exists(char const *fileName); // (2)
For the first prototype (1), most people will expect the function to
return true if the given filename is the name of an existing
file. However, using the second prototype some ambiguity arises: intuitively
the returnvalue 1 is appealing, as it leads to constructions like
if (exists("myfile"))
cout << "myfile exists";
On the other hand, many functions (like access(), stat(), etc.) return
0 to indicate a successful operation, reserving other values to indicate
various types of errors.
As a rule of thumb we suggest the following: If a function should inform its
caller about the success or failure of its task, let the function return a
bool value. If the function should return success or various types of
errors, let the function return enum values, documenting the situation
when the function returns. Only when the function returns a meaningful
integral value (like the sum of two int values), let the function return
an int value.
wchar_t type is an extension of the char basic type, to accomodate
wide character values, such as the Unicode character set.
Sizeof(wchar_t) is 2, allowing for 65,536 different character values.
Note that a programming language like Java has a data type char that
is comparable to C++'s wchar_t type, while Java's byte data
type is comparable to C++'s char type. Very convenient....
const very often occurs in C++ programs, even though it
is also part of the C grammar, where it's much less used.
This keyword is a modifier which states that the value of a variable or of an
argument may not be modified. In the below example an attempt is made to
change the value of a variable ival, which is not legal:
int main()
{
int const // a constant int..
ival = 3; // initialized to 3
ival = 4; // assignment leads
// to an error message
return (0);
}
This example shows how ival may be initialized to a given value in its
definition; attempts to change the value later (in an assignment) are not
permitted.
Variables which are declared const can, in contrast to C, be used as
the specification of the size of an array, as in the following example:
int const
size = 20;
char
buf[size]; // 20 chars big
A further usage of the keyword const is seen in the declaration of
pointers, e.g., in pointer-arguments. In the declaration
char const *buf;
buf is a pointer variable, which points to chars. Whatever is
pointed to by buf may not be changed: the chars are declared as
const. The pointer buf itself however may be changed. A statement as
*buf = 'a'; is therefore not allowed, while buf++ is.
In the declaration
char *const buf;
buf itself is a const pointer which may not be changed. Whatever
chars are pointed to by buf may be changed at will.
Finally, the declaration
char const *const buf;
is also possible; here, neither the pointer nor what it points to may be
changed.
The rule of thumb for the placement of the keyword const is the
following: whatever occurs just prior to the keyword may not be changed.
The definition or declaration in which const is used should be read
from the variable or function identifier back to the type indentifier:
``Buf is a const pointer to const characters''This rule of thumb is especially handy in cases where confusion may occur. In examples of C++ code, one often encounters the reverse:
const
preceding what should not be altered. That this may result in sloppy
code is indicated by our second example above:
char const *buf;
What must remain constant here? According to the sloppy interpretation, the
pointer cannot be altered (since const precedes the pointer-*). In fact,
the charvalues are the constant entities here, as will be clear when it is
tried to compile the following program:
int main()
{
char const *buf = "hello";
buf++; // accepted by the compiler
*buf = 'u'; // rejected by the compiler
return (0);
}
Compilation fails on the statement *buf = 'u';, not on the statement
buf++.
int
int_value;
int
&ref = int_value;
In the above example a variable int_value is defined. Subsequently a
reference ref is defined, which due to its initialization addresses the
same memory location which int_value occupies. In the definition of
ref, the reference operator & indicates that ref is not
itself an integer but a reference to one. The two statements
int_value++; // alternative 1
ref++; // alternative 2
have the same effect, as expected. At some memory location an int value
is increased by one --- whether that location is called int_value or
ref does not matter.
References serve an important function in C++ as a means to pass arguments
which can be modified (`variable arguments' in Pascal-terms). E.g., in
standard C, a function which increases the value of its argument by five
but which returns nothing (void), needs a pointer argument:
void increase(int *valp) // expects a pointer
{ // to an int
*valp += 5;
}
int main()
{
int
x;
increase(&x) // the address of x is
return (0); // passed as argument
}
This construction can also be used in C++ but the same effect
can be achieved using a reference:
void increase(int &valr) // expects a reference
{ // to an int
valr += 5;
}
int main()
{
int
x;
increase(x); // a reference to x is
return (0); // passed as argument
}
The way in which C++ compilers implement references is actually by
using pointers: in other words, references in C++ are just ordinary
pointers, as far as the compiler is concerned. However, the programmer does
not need to know or to bother about levels of indirection. (Compare
this to the Pascal way: an argument which is declared as var is in fact
also a pointer, but the programmer needn't know.)
It can be argued whether code such as the above is clear: the statement
increase (x) in the main() function suggests that not x
itself but a copy is passed. Yet the value of x changes because of
the way increase() is defined.
Our suggestions for the usage of references as arguments to functions are
therefore the following:
void some_func(int val)
{
printf("%d\n", val);
}
int main()
{
int
x;
some_func(x); // a copy is passed, so
return (0); // x won't be changed
}
void by_pointer(int *valp)
{
*valp += 5;
}
void by_reference(int &valr)
{
valr += 5;
}
int main ()
{
int
x;
by_pointer(&x); // a pointer is passed
by_reference(x); // x is altered by reference
return (0); // x might be changed
}
struct, is passed as argument, or is returned from the function.
In these cases the copying operations tend to become
significant factors when the entire structure must be copied, and it is
preferred to use references. If the argument isn't changed by the
function, or if the caller shouldn't change the returned information,
the use of the const keyword is appropriate and should be used.
Consider the following example:
struct Person // some large structure
{
char
name [80],
address [90];
double
salary;
};
Person
person[50]; // database of persons
void printperson (Person const &p) // printperson expects a
{ // reference to a structure
printf ("Name: %s\n" // but won't change it
"Address: %s\n",
p.name, p.address);
}
Person const &getperson(int index) // get a person by indexvalue
{
...
return (person[index]); // a reference is returned,
} // not a copy of person[index]
int main ()
{
Person
boss;
printperson (boss); // no pointer is passed,
// so variable won't be
// altered by function
printperson(getperson(5)); // references, not copies
// are passed here
return (0);
}
References also can lead to extremely `ugly' code. A function can also return
a reference to a variable, as in the following example:
int &func()
{
static int
value;
return (value);
}
This allows the following constructions:
func() = 20;
func() += func ();
It is probably superfluous to note that such constructions should not normally
be used. Nonetheless, there are situations where it is useful to return a
reference. Even though this is discussed later, we have seen an example
of this phenomenon at our previous discussion of the iostreams. In a
statement like cout << "Hello" << endl;, the insertion operator returns
a reference to cout. So, in this statement first the "Hello" is
inserted into cout, producing a reference to cout. Via this reference
the endl is then inserted in the cout object, again producing a
reference to cout. This latter reference is not further used.
A number of differences between pointers and references is pointed out in the
list below:
int &ref;
is not allowed; what would ref refer to?
external.
These references were initialized elsewhere.
& is used with a reference,
the expression yields the address of the variable to which the reference
applies. In contrast, ordinary pointers are variables themselves, so the
address of a pointer variable has nothing to do with the address of the
variable pointed to.
structs (see
section 2.5.12). Such functions are called member
functions or methods.
This section discusses the actual definition of such functions.
The code fragment below illustrates a struct in which data fields for a
name and address are present. A function print() is included in the
struct definition:
struct person
{
char
name [80],
address [80];
void
print (void);
};
The member function print() is defined using the structure name
(person) and the scope resolution operator (::):
void person::print()
{
printf("Name: %s\n"
"Address: %s\n", name, address);
}
In the definition of this member function, the function name is preceded by
the struct name followed by ::. The code of the function shows how
the fields of the struct can be addressed without using the type name: in
this example the function print() prints a variable name. Since
print() is a part of the struct person, the variable name
implicitly refers to the same type.
The usage of this struct could be, e.g.:
person
p;
strcpy(p.name, "Karel");
strcpy(p.address, "Rietveldlaan 37");
p.print();
The advantage of member functions lies in the fact that the called function
can automatically address the data fields of the structure for which it was
invoked. As such, in the statement p.print() the structure p is the
`substrate': the variables name and address which are used in the
code of print() refer to the same struct p.
C++ has two special keywords which are concerned with data hiding:
private and public. These keywords can be inserted in the definition
of a struct. The keyword public defines all subsequent fields of a
structure as accessible by all code; the keyword private defines all
subsequent fields as only accessible by the code which is part of the
struct (i.e., only accessible for the member functions) (Besides
public and private, C++ defines the keyword protected.
This keyword is not often used and it is left for the reader to
explore.). In a struct all fields are public, unless
explicitly stated otherwise.
With this knowledge we can expand the struct person:
struct person
{
public:
void
setname (char const *n),
setaddress (char const *a),
print (void);
char const
*getname (void),
*getaddress (void);
private:
char
name [80],
address [80];
};
The data fields name and address are only accessible for the member
functions which are defined in the struct: these are the functions
setname(), setaddress() etc.. This property of the data type is
given by the fact that the fields name and address are preceded by
the keyword private. As an illustration consider the following code
fragment:
person
x;
x.setname ("Frank"); // ok, setname() is public
strcpy (x.name, "Knarf"); // error, name is private
The concept of data hiding is realized here in the following manner. The
actual data of a struct person are named only in the structure
definition. The data are accessed by the outside world by special functions,
which are also part of the definition. These member functions control all
traffic between the data fields and other parts of the program and are
therefore also called `interface' functions.
The data hiding which is thus realized is illustrated further in
figure 2.
Also note that the functions setname() and setaddress() are declared
as having a char const * argument. This means that the
functions will not alter the strings which are supplied as their arguments.
In the same vein, the functions getname() and getaddress() return a
char const *: the caller may not modify the strings which are
pointed to by the return values.
Two examples of member functions of the struct person are shown
below:
void person::setname(char const *n)
{
strncpy(name, n, 79);
name[79] = '\0';
}
char const *person::getname()
{
return (name);
}
In general, the power of the member functions and of the concept of data
hiding lies in the fact that the interface functions can perform special
tasks, e.g., checks for the validity of data. In the above example
setname() copies only up to 79 characters from its argument to the data
member name, thereby avoiding array boundary overflow.
Another example of the concept of data hiding is the following. As an
alternative to member functions which keep their data in memory (as do the
above code examples), a runtime library could be developed with interface
functions which store their data on file. The conversion of a program which
stores person structures in memory to one that stores the data on disk
would mean the relinking of the program with a different library.
Though data hiding can be realized with structs, more often (almost
always) classes are used instead. A class is in principle equivalent to a
struct except that unless specified otherwise, all members (data or
functions) are private. As far as private and public are
concerned, a class is therefore the opposite of a struct. The
definition of a class person would therefore look exactly as shown
above, except for the fact that instead of the keyword struct, class
would be used. Our typographic suggestion for class names is a capital as
first character, followed by the remainder of the name in lower case (e.g.,
Person).
structs are concerned. In C it is
common to define several functions to process a struct, which then
require a pointer to the struct as one of their arguments. A fragment
of an imaginary C header file is given below:
// definition of a struct PERSON_
typedef struct
{
char
name[80],
address[80];
} PERSON_;
// some functions to manipulate PERSON_ structs
// initialize fields with a name and address
extern void initialize(PERSON_ *p, char const *nm,
char const *adr);
// print information
extern void print(PERSON_ const *p);
// etc..
In C++, the declarations of the involved functions are placed inside the
definition of the struct or class. The argument which denotes which
struct is involved is no longer needed.
class Person
{
public:
void initialize(char const *nm, char const *adr);
void print(void);
// etc..
private:
char
name[80],
address[80];
};
The struct argument is implicit in C++. A function call in C
like
PERSON_
x;
initialize(&x, "some name", "some address");
becomes in C++:
Person
x;
x.initialize("some name", "some address");