

Arquitectura
Arquitectura AMD x86-64
 A arquitectura AMD x86-64 é uma
inovação da AMD que estende o x86, o conjunto de instruções mais amplamente
suportado do mercado. Esta foi desenvolvida para permitir o uso da computação
de 64 bits e ao mesmo tempo permanecer compatível com a vasta
infra-estrutura de software já existente para x86.
A arquitectura AMD x86-64 é uma
inovação da AMD que estende o x86, o conjunto de instruções mais amplamente
suportado do mercado. Esta foi desenvolvida para permitir o uso da computação
de 64 bits e ao mesmo tempo permanecer compatível com a vasta
infra-estrutura de software já existente para x86.
A estratégia de 64 bits da AMD permite que as últimas inovações nos processadores funcionem tranquilamente com a base instalada de aplicativos e sistemas operacionais de 32 bits, iniciando o estabelecimento de uma base instalada com suporte para 64 bits. Assim o mercado pode avançar o desenvolvimento de software em todas as frentes, mantendo a compatibilidade com a plataforma x86, e ao mesmo tempo desfrutando os benefícios da tecnologia de 64 bits.
A necessidade de tecnologia de 64 bits é orientada pelas aplicações que enderecem grandes quantidades de memória física e virtual, como por exemplo servidores de alta performance, sistemas de gerência de bancos de dados e ferramentas de CAD. A evolutiva abordagem da AMD para a tecnologia de 64 bits permite a transição gradual do software de 32 bits para 64 bits.
Arquitectura Hammer
A arquitetura “Hammer” foi projectada para proporcionar uma performance sem semelhança. Esta arquitectura suporta o conjunto de instruções x86-64, oferecendo excepcional performance tanto para código de 32 bits como para o de 64 bits. Á medida que aplicações de 64 bits com uso intensivo de memória se for intensificando, existirá uma transformação de aplicações do código de 32 bits para o de 64 bits de forma integrada. A abordagem evolutiva da AMD para a tecnologia de 64 bits permite a transição gradual do software de 32 bits para 64 bits.
Actualmente os microprocessadores AMD Athlon e AMD Duron utilizam tecnologia de Socket A, mas com a implementação da arquitetura “Hammer” na futura linha de microprocessadores da AMD, será necessário a implementação de um novo socket.
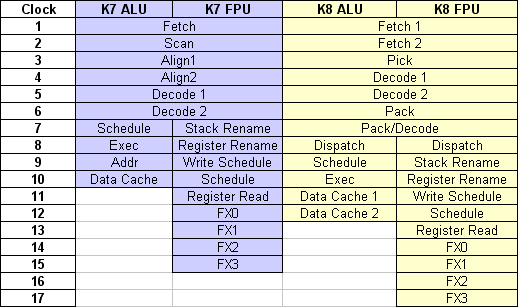
Study of the K8
O core K7 da Athlon tem uma longa história, desde o primeiro Athlon Slot A 500MHz até ao último Barton. No entanto, o core K7 não evoluiu muito na sua história, as únicas mudanças dizem respeito á cache L2, e no caso do Athlon XP o uso do SSE intruction set. Isto pode ser explicado com o facto do core Athlon ter sido originalmente equipado com poderosas características, que o tornáram eficiente assim que foi lançado. Podemos referir:
3 unidades de decoding x86
3 unidades de inteiros (ALU)
3 unidades de vírgula flutuante (FPU)
1 cache L1 de 128KB
As unidades do K7 permitem suportar até 9 instruções por ciclo de relógio, e uma das chaves desta eficiência está relacionada com as muitas unidades que inclui, especialmente as 3 FPUs que fazem do K7 o mais poderoso CPU para computação de vírgula flutuante.
O design do core ou núcleo K8 foi em grande parte inspirado pelo K7. As diferenças entre os dois consistem em pequenas diferenças e melhoramentos. Ao contrário do normal, a mudança na geração de CPUs não foi devida a uma grande evolução no core em si, mas sim uma evolução na maneira como o CPU opera, nomeadamente os 64 bits.
O core K8:
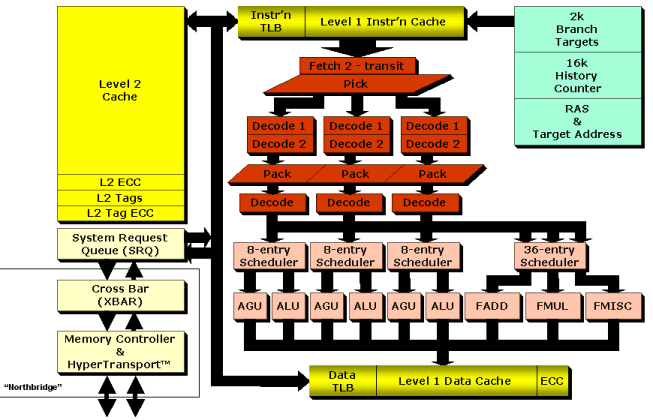
Como podemos ver o K8 é bastante parecido com o K7, pelo que conseguimos ver as mesmas unidades. No entanto, uma diferença entre os dois cores consiste na subdivisão da pipeline. A pipeline do K7 tem um design muito específico: é dividido em duas partes, um para a computação de inteiros, outro para a computação de vírgula flutuante. A fase de "Fetch/Decode". que consiste nas primeiras 6 etapas da pipeline, é comum aos dois tipos de instruções. As fases de Execução ("Execution") já são diferentes: 4 passos para a pipeline de inteiros (prefazendo 10 no total), e 9 para vírgula flutuante (prefazendo 15 no total). Vemos pois que a computação de inteiros não é atrasada por uma pipeline muito longa.
O K8 usa também uma pipeline dividida, mas dois passos são acrescentados por cada "branch". A pipeline de inteiros é agora de 12 passos e a de vírgula flutuante de 17:
As inovações do K8
A fase de "Fetch/Decode" foi redesenhada no K8, e tem agora 7 passos. Inclui um passo adicional que compacta alguma instruções antes de as enviar para a proxima fase.
Vejamos em detalhe as instruções na pipeline do K8:
A fase de Fetch é capaz de alimentar os 3 descodificadores com 16 bytes de instruções por cada ciclo de relógio. O processo de fetching usa o código da cache L1 e a "branch prediction logic".
Os decoders convertem as instruções x86 em micro operações de tamanho fixo
As instruções complexas, que são descodificadas em mais de 2 µOPs, são descodificadas usando um ROM interno, que necessita de mais tempo. Estas instruções são então "microcoded".
3 unidades de adress generation (AGU)
3 unidades de inteiros (ALU). Estas unidades são capazes de realizar quase todas as operarações em um ciclo, tanto em 32 como em 64 bits: adição, rotação, shift, operações lógicas (and, or). A multiplicação de inteiros tem uma latência de 3 ciclos de relógio em 32 bits e de 5 ciclos em 64 bits.
3 unidades de vírgula flutuante (FPU), que suportam x87, MMX, 3DNow!, SSE e SSE2.
A última fase da pipeline consiste na fase Load/Store. Esta fase usa a cache L1. A L1 é dual-ported, o que significa que suporta 2 escritas ou leituras de 64 bits por cada ciclo de relógio.

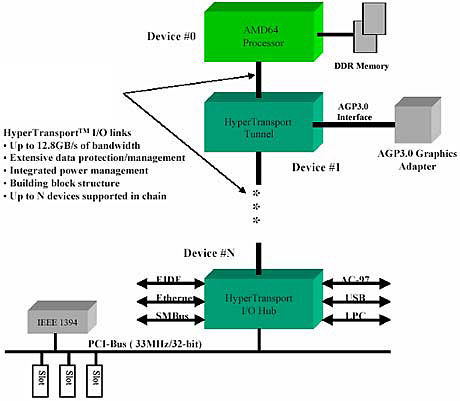
Para além dos melhoramentos do core, o K8 introduz duas grande inovações ao introduzir novas características no CPU: o controlador de memória DDR e o interface HyperTransport.
Controlador de memória integrado
A inserção do controlador de memória no core do CPU representa uma grande mudança na relação entre os componentes da motherboard, visto o controlo de memória ser antigamente feito pelo "northbridge" do chipset.
O diagram seguinte mostra a relação clássica entre o CPU e o controlador de memória. Este exemplo pode ser um Pentium 4 com 200MHz de FSB:

O gerador de relógio gera 200MHz para o "northbridge", isto é o front side bus (FSB). O bus entre o "northbridge" e o CPU tem 64 bits a 200MHz, mas 4 pacotes de 64 bits são enviados por cada ciclo de relógio. Isto é como se o o FSB fosse 4x200MHz, daí que a velocidade de bus seja por vezes reportada como sendo 800MHz.
O K8 é um pouco diferente:

O relógio conduz sempre o "northbridge", e disponibiliza a freqência de referência para a ligação de HyperTransport entre o "northbridge" e o CPU. A frequência de HyperTransport pode ser considerada o FSB, porque o CPU usa esta frequência para gerar o seu próprio relógio interno, através de um multiplicador interno.
Como mostrado no diagrama, a velocidade do controlador de memória é a mesma da velocidade do CPU. Pedidos à memória são consequentemente enviados à velocidade do CPU, num bus de 64 ou 128, dependendo do número de canais de memória. Podemos ver que não há agora ligação entre o gerador de relógio e a memória. A velocidade de memória é obtida a partir do relógio do CPU, dividido por um factor que depende das especificações da memória.
A tabela abaixo mostra os divisores usados de acordo com a frequência do CPU e com a velocidade dos pedidos da memória.
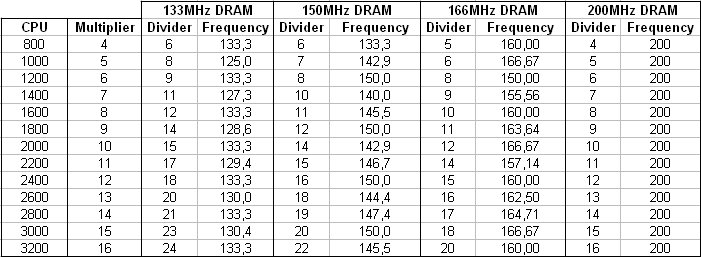
Como é obvio, o controlador de memória integrada não melhora a largura de banda da memória, mas reduz drasticamente o tempo de pedido (request time).
O problema da integração do controlador de memória é a falta de flexibilidade. O controlador é dedicado a uma tecnologia de memória, e qualquer mudança nos standards de memória necessitarão de uma mudança no design do CPU. Como se sabe, isto não ocorre muito frequentemente (pelo menos não tão frequentemente como as famílias de CPU mudam), mas isto pode aumentar drasticamente o preço do CPU, visto o seu processo necessita de ser mudado.
Tecnologia HyperTransport
A tecnologia HyperTransport é um link ponto-a-ponto de alta velocidade e performance para a conexão de circuitos integrados numa motherboard. Utilizando um número equivalente de pinos, ela pode ser significativamente mais rápida do que um PCI. A tecnologia HyperTransport foi criada pela AMD e aperfeiçoada com a ajuda de diversos parceiros do mercado. Ela pode ser utilizada principalmente nos sectores de Tecnologias de Informação e telecomunicações, mas qualquer aplicação que requer alta velocidade, baixa latência e escalabilidade pode se beneficiar da tecnologia HyperTransport. A tecnologia HyperTransport foi desenvolvida para aproveitar a tremenda potência dos microprocessadores AMD. Permite trocas com baixa latência, o que é bastante relevante para comunicações de CPUs. Usa um bus de 16 bits a 800MHz, e usa um "date rate system" duplo, que permite alcançar um pico de largura de banda de 3,2 Gb.
A tecnologia HyperTransport foi desenvolvida para fornecer significativamente mais largura de banda do que as tecnologias actuais; para utilizar respostas de baixa latência e menos pinos; para ser compatível com os barramentos dos PCs existentes e extensível aos novos barramentos SNA (Systems Network Architecture), e para ser transparente aos sistemas operacionais e afetar minimamente os drivers dos periféricos.
A arquitetura “Hammer” foi projetada para suportar até três links HyperTransport, sendo a largura de banda máxima combinada das conexões HyperTransport de 19,2 GB/s.
Cool'n'Quiet
Cool'n'Quiet não é realmente um melhoramento técnico, mas algo que melhora o conforto de um sistema K8. CnQ não é mais que a tecnologia PowerNow! do Athlon Mobile, mas usado para CPUs de desktop. Reduz ou aumenta o relógio do CPU e a voltagem do core de acordo com a carga do CPU. Isto permite reduzir o consumo do computador, a velocidade da ventoinha (e ruído), as temperaturas, e melhorar o tempo de vida do PC. A mudança de estados é tão rápida que a perda de performance é insignificante. Uma medida muito útil, que merecia ser mencionada.
Nem todos os K8 suportam Cool'n'Quiet. Apenas os Athlon FX e 64, o Opteron não.
Caches do K8
cache L1
|
CPU |
K8 |
Athlon XP |
Pentium 4 Northwood |
Pentium 4 Prescott |
|
Size |
code : 64KB |
code : 64Ko |
TC : 12Kµops |
TC : 12Kµops |
|
Associativity |
code : 2 way |
code : 2 way |
TC : 8 way |
TC : 8 way |
|
Cache line size |
code : 64 bytes |
code : 64 bytes |
TC : n.a |
TC : n.a |
|
Write policy |
Write Back |
Write Back |
Write Through |
Write Through |
|
Latency |
3 cycles |
3 cycles |
2 cycles |
4 cycles |
O código L1 e os dados das caches L1 do K8 são semelhantes aos do K7. Isto parece lógico atendendo ao core destes dois CPUs. Uma cache de grande dimensão é bastante eficiente como nos mostrou o K7 no passado. Usa uma associatividade 2-way, que resulta numa organização de dois blocos de 32Kb. O tamanho desses blocos permitem-lhes conter uma vasta quantidade de dados os código na mesma área de memória, mas a baixa associatividade tende a criar conflitos durante a fase de "caching".
cache L2
|
CPU |
K8 |
Athlon XP |
Pentium 4 Northwood |
Pentium 4 Prescott |
|
Size |
512KB (NewCastle) |
256 and 512KB |
512KB |
1024KB |
|
Associativity |
16 way |
16 way |
8 way |
8 way |
|
Cache line size |
64 bytes |
64 bytes |
64 bytes |
64 bytes |
|
Latency |
? |
8 cycles |
7 cycles |
11 cycles |
|
Bus width |
128 bits |
64 bits |
256 bits |
256 bits |
|
L1 relationship |
exclusive |
exclusive |
inclusive |
inclusive |
Mais uma vez, a cache L2 do K8 partilha muitas características com a da K7. Ambas usam uma associatividade 16-way que parcialmente compensa a baixa associatividade da L1. A banda do bus entre o core e a cache L2 aumenta, de 64 bits no K7 para 128 bits no K8. No K7, este bus tem o tamanho de acordo com as especificações do primeiro Athlon com uma cache discreta, mas agora esta escolha começa a mostrar algumas limitações nas últimas "on-speed full-speed caches".
O K7 e o K8 usam uma relação exclusiva entre a L1 e a L2, em oposição à Intel que usa uma relação inclusiva. Este escolha tem uma série de repercursões na arquitectura global das caches.
Caches inclusivas e exclusivas
Consideremos que o CPU tem apenas um nível de cache. Quando um pedido de leitura ocorre, o CPU fará um pedido à sua cache pelos dados requeridos. Se esta não contém os dados, o CPU irá buscá-los à memória e ao mesmo tempo copiá-los para a sua cache. O porquê desta acção deve-se ao facto de que o CPU assume que se os dados foram necessários uma vez, poderão ser usados outra vez num futuro próximo. Estatisticamente este facto tem grandes chances de ocorrer.
Um CPU x86 contém um pequeno número de registos, e o valor que acabou de obter da memória não ficará nos registos mais que 2 ou 3 ciclos de relógio, isto porque o registo será usado para outra instrução. Armazenar os dados em cache é uma maneira de manter os dados não "muito longe".
Com um nível de cache, um pedido de leitura por parte dos CPU tem dois fins possíveis:
Se os dados estão na cache, ocorre um chamado hit ou cache success. É obviamente o caso mais favorável.
Se os dados não se encontram na cache, ocorre um chamado cache miss. Os passos seguites consistem em ir buscar os dados à memória e copiá-los para a cache. Este processo é chamado de "caching" ou "cache-fill". Neste momento dois casos podem ocorrer, dependendo se a cache já se encontra cheia ou não. Se ainda não está cheia uma nova linha da cache é preenchida.
Figura 1 : cache fill
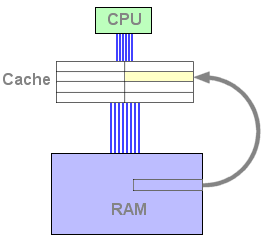
A situação torna-se complicada se a cache já se encontra cheia. Terá então que uma linha da cache que ser substítuida. De maneira a saber qual a linha a ser substítuida, o CPU usa um algoritmo de substituição. A escolha mais comum é substituir a linha menos usada recentemente: este algoritmo é o LRU (Least Recently Used).
Figura 2 : Substituição de uma cache line
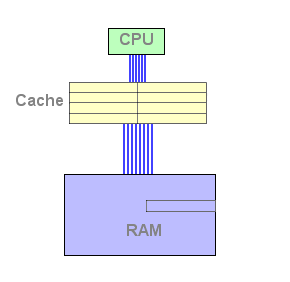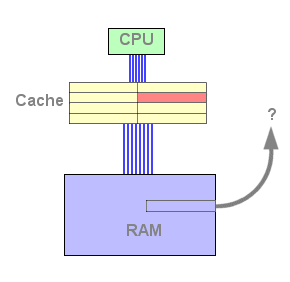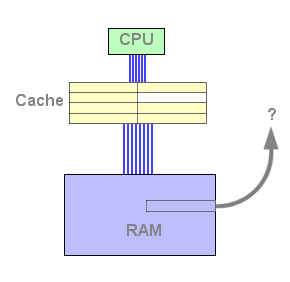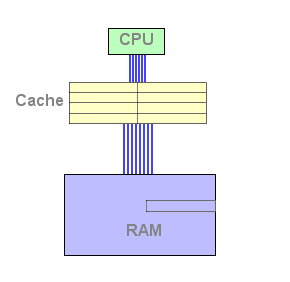
Como mostra a animação, a linha da cache substituida é simplesmente perdida. O objectivo da cache de segundo nível é ficar com esta linha em vez de a apagar. É uma espécie de reciclagem.
The addition of a 2nd level cache creates new possible states when a read request occurs :
A introdução de uma cache de segundo nível cria novos estados quando um pedido de escrita ocorre:
os dados estão em L1 -> sucesso L1
os dados não estão em L1 mas estão em L2 -> miss em L1, hit em L2
os dados não estão nem em L1 nem em L2 -> miss em L1 e L2
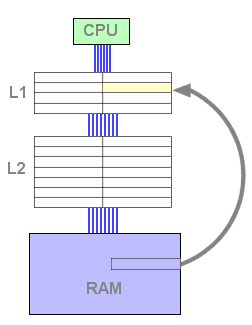
Vejamos como isto funciona. Enquanto a cache L1 não está cheia, a fase de "caching" é igual a uma configuração de apenas um nível de caching:
Figura 3 : L1 cache fill
Assim que a cache L1 está cheia, a L2 toma um papel importante: quando uma linha é retirada da L1, esta é copiada para a L2, e uma linha nova da memória é copiada para a linha livre da L1 :
Figura 4 : L2 fill
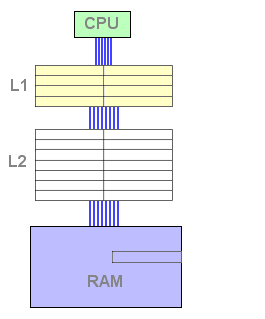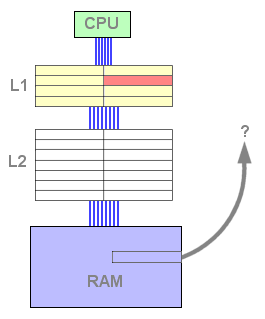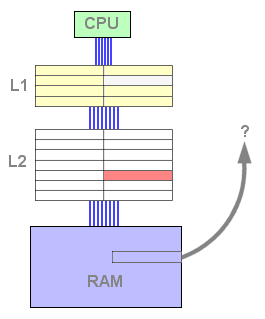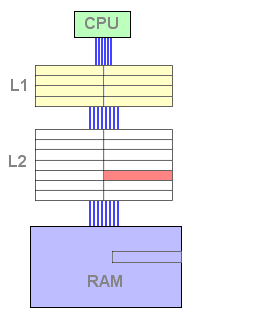
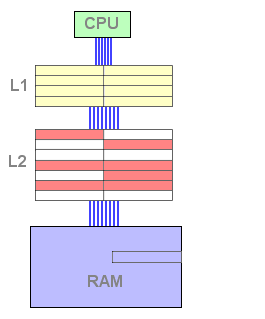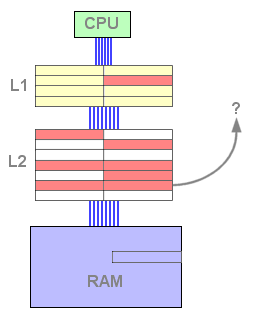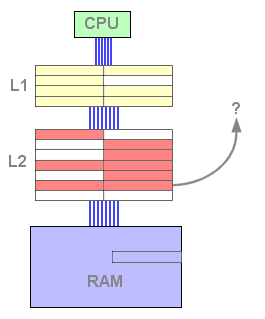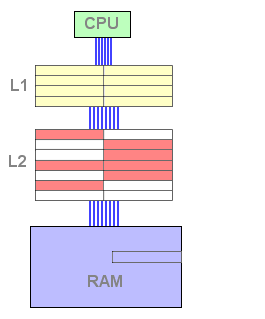
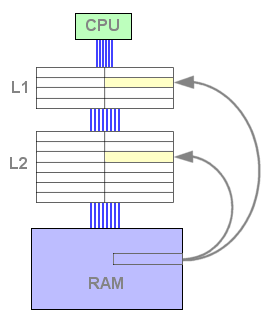
A partir deste momento, a cache L2 contém dados e está pronta a responder a um pedido de leitura. Se os dados pedidos não se encontrarem na L1 mas sim na L2, a linha é copiada uma vez mais para a L1. Isto implica que uma linha terá que ser libertada da L1 de modo a receber os dados da L2. O algoritmo LRU selecciona a linha, copia-a para a L2, e a linha pedida é copiada para a L1 novamente.
Figura 5 : L1 miss, L2 hit
Vemos por isto que uma linha de cache nunca se encontra ao mesmo tempo na cache L1 e na cache L2. Isto significa que a L1 e a L2 nunca contêm os mesmos dados. Estes estão exclusivamente num nível de cache - relação exclusiva.
O tamanho total da cache é consequentemente a soma do tamanho dos dois níveis de cache. Este método trabalha independentemente do tamanho da L1 e da L2, podendo mesmo a L2 ser menor que a L1.
A relação de exclusividade permite uma grande flexibilidade, mas perde em performance. Na verdade, quando ocorre um hit na cache L2, uma linha da L1 tem de ser copiada para a L2 antes de receber os dados da L2. Este passo adicional necessita de uma grande quantidade de ciclos de relógio, e aumenta o tempo necessário para obter os dados da L2. De maneira a acelerar o processo, as caches exclusivas frequentemente usam uma "victim buffer" (VB), que é uma pequena e rápida memória entre a cache L1 e a L2. A linha que sai da L1 é então copiada para a VB em vez de o ser para a L2. Ao mesmo tempo, o pedido de leitura da L2 começa, fazendo com que a operação de escrita da L1 para a VB seja escondida pela latência da L2.
A VB é um bom melhoramento na relação de exclusividade, mas é muito limitada em tamanho (geralmente entre 8 e 16 linha). Para além disso, quando a VB se encontra cheia, terá de ser despejada para a L2, que requer ciclos de relógio extra.
Na verdade, de maneira a evitar uma escrita adicional na L2 em caso de um hit na L2, esta escrita deverá ser feita antes. Isto é, a linha em causa já veio de L1, então já foi escrita na L1 anteriormente. Logo, se essa linha é copiada ao mesmo tempo, já estará na L2.
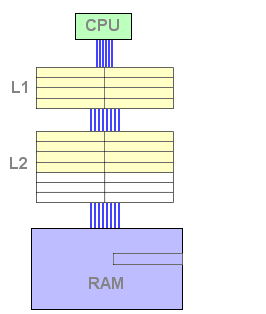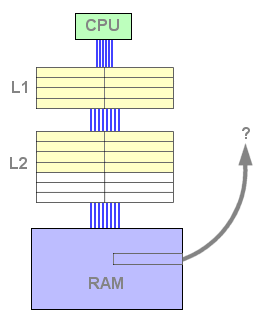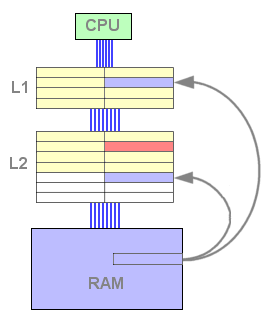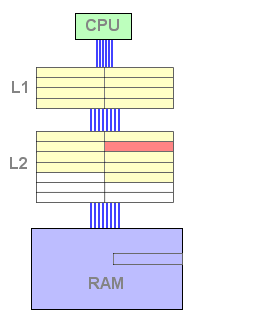
Nesta configuração, os dados são tirados da memória e copiados para a L1 e para a L2. Assim sendo, o passo de "caching" necessitará de duas escritas em vez de uma.
Figura 6 : Caching
Uma vez a L1 cheia e os dados pedidos não estão em nenhum nível de cache, uma nova linha é então copiada para ambos os níveis. Isto resultará na eliminação de uma linha em L1, mas não há necessidade de a salvar para a L2 porque ela já la estará. Então, o número total de escritas será o mesmo que na configuração anterior. A partir deste ponto, a cache L2 irá conter dados que não estarão em L1.
Figura 7 : L1 e L2 miss
Se existir apenas um hit em L2, a única operação necessária será copiar a linha de L2 para L1. Então, apenas uma escrita será necessária em vez de duas como na configuração anterior.
Figura 8 : L1 miss, L2 hit
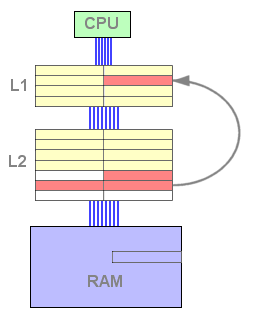
Nesta configuração, todas as linhas de L1 estão duplicadas em L2. Isto é uma relação inclusiva.
Uma cache inclusiva permite evitar uma escrita em caso de um hit em L2, que a fará mais rápida que a cache exclusiva para este passo. Na prática, uma cache L2 inclusiva é mais rápida que uma exclusiva. Por outro lado, a duplicação da L1 na L2 reduz o espaço útil da cache L2. Isto significa que:
o tamanho da L2 terá de ser maior que o tamanho da L1, e a eficiência da L2 dependerá nesta diferença de tamanho.
o tamanho de cache útil é : tamanho de L1 + tamanho de L2 - tamanho de L1, logo o tamanho de L2.
Vantagens e desvantagens de cada método
O melhor e pior de uma cache exclusiva:
|
+ |
- |
|
|
Perante isto podemos dizer que o aspecto de uma cache exclusiva será:
Uma cache L1 de grande tamanho.
Uma "victim buffer" para aumentar a performance.
A AMD fez a escolha de uma relação exclusiva pela primeira vez no "Thunderbird". A arquitectura do CPU encaixa nesta escolha, com uma grande cache L1 e uma "victim buffer" de 8 entradas.
Esta escolha permitiu à AMD construir CPUs com uma cache L2 de 64 até 512Kb com o mesmo core, e mesmo o Duron que tem uma cache L2 de 64Kb oferece uma boa performance. No entanto, o aumento do tamanho da L2 não oferece uma grande salto em performance.
Comparativamente, uma cache inclusiva :
|
+ |
- |
|
|
Esta tabela é exactamente o oposto da tabela da cache exclusiva. De facto, a única vantagem de uma cache inclusiva é a performance, mas o melhoramento necessita de algumas condições para ser respeitado. É difícil por isso de imaginar como será uma cache inclusiva perfeita. A limitação no tamanho da relação L1/L2 faz com que a L1 seja pequena, mas uma L1 pequena resultará na redução da taxa de sucesso (hits), e consequentemente na sua performance. Por outro lado, se for grande demais, a relação será muito grande para uma boa performance da L2.
Conclusão
A escolha de uma arquitectura de cache é um passo muito importante na construção de um CPU, visto que determina a sua performance, mas também a sua evolução.
A relação exclusiva é a mais flexível, visto que permite uma variedade de configurações com boas performances. A desvantagem é que a performance não aumenta muito com o tamanho da cache L2. A relação incluisva apenas pode ser escolhida com um propósito de performance, sabendo que por exemplo que aumentando o tamanho da L2 a performance também aumentará em flecha. No entanto, as limitações deste método são muito fortes, e o não respeitos destas pode ter o resultado oposto e consequentemente uma quebra de performance.
Tecnologia AMD64
O grande desafio do K8 reside na introdução da tecnologia a 64 bits, chamada x86-64 ou AMD64.
O AMD64 vem repetir o desafio do 386: nada mais nada menos que mudar a arquitectura x86. É necessário compreender quanto tempo foi preciso para a tecnologia a 32 bits estar presente em todos os sistemas, 10 anos após a introdução do 386. Hoje em dia, os sistemas são 50 ou 100 vezes mais rápidos que o 386, mas isto é apenas devido à evolução das arquitecturas do CPU, porque o código para o 386 ainda hoje é usado. O K8 promete uma aceleração que justifiará uma mudança da geração dos CPU dos K7, mas a maneira que é usada é especialmente uma técnica de software. Uma alternativa na corrida tecnológica que fará as arquitecturas de CPUs mais e mais complexas. Na verdade, o sucesso do AMD64 depende do software, e primeiro que tudo nos sistemas operativos. Desta vez, um passo na arquitectura dos PCs não será medida no número de transistores.
O AMD levanta uma série de questões: o que poderá oferecer hoje uma tecnologia a 64 bits?, precisaremos mesmo dela agora?
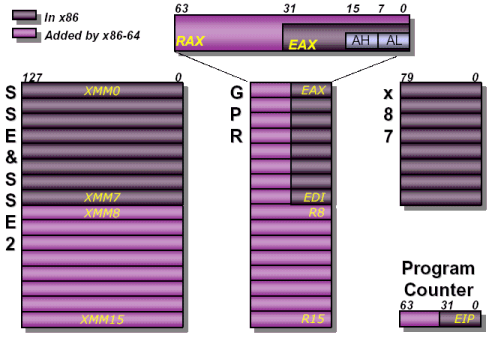
Os GPR
O facto de um processador ser de 26, 32 ou 64 bits reside no tamanho dos seus General Purpose Registeres, ou GPR. Os GPR são os registos de trabalho do CPU: eles são os operandos do "x86 instruction set", e são eles os únicos registos que podem ser usados para endereçar memória. Isto significa que a memória que o CPU pode endereçar depende do tamanho dos GPR.
O primeiro processador x86, o 8086, usava oito 16 bits GPR: ax, bx, cx, dx, si, di, bp, sp. Os 16 bits de GPR permitiam armazenar endereços de memória entre 0 e 65535, o que representa 64Kb de memória endereçável. Como é obvio isto não é suficiente, mesmo para o 8086. O truque consiste em extender a gama de endereçamento manuseando a memória em blocos, cada um deles de, como é óbvio, de 64Kb. Este método porém não oferece uma grande flexibilidade.
A introdução do 386 permitiu ultrapassar esta limitação. O 386 aumentou o tamanho dos GPR para 32 bits, e criou-se o primeiro processador IA32 (Intel Architecture 32 bits), e permitiu endereçar até 4Gb de memória. De maneira a ser compativel com os programas de 8 e 16 bits, os GPR do 386 conseguiam tanto usar registos de 8 como de 16 bits. Para um programa usar os GPR como registos de 32 bits, o 386 precisava de ser mudado para um modo específico, chamado protected mode.
Limitações do IA32
A primeira limitação é uma limitação horizontal, visto que diz respeito ao tamanho dos GPR, e especialmente a memória endereçavel com GPR de 32 bits. 4Gb é ainda um valor bastante grande para computadores pessoais, mas não para servidores. Na prática, a barreira dos 4Gb pode ser ultrapassada graças a um mecanismo de extensão similar ao usado no 8086.
A segunda limitação diz respeito ao número de GPR (limitação vertical). O número de GPR não se alterou desde a introdução do x86. Claro que o x86 foi aprefeiçoado, especialmente com extensões dos "instructions sets", que troxeram novos registos: oito registos de 80 bits para x87, MMX e 3DNow!, oito registos de 128 bits para o SSE 1, 2 e 3. Mas este registos não são GPR, mas sim registos de cálculo, não permitindo o endereçamento de memória.
O pequeno número de GPR tem um efeito directo na eficiência do código x86. Na verdade, a limitação não provém do CPU mas sim dos compiladores. Os CPUs evoluiram, mas também os programas. Estes são cada vez maiores e mais complexos, e não se assemelham em nada aos dedicados ao 8086. Os compiladores tem por isso mais trabalho, mas as mesmas ferramentas, nomeadamente apenas oito GPR. Consequentemente, os compiladores necessitam de jogar com os registos, e muitas das instruções são geradas com o propósito exclusivo de libertar vários registos, usando pilhas ou a memória. A presença destas instruções aumentam o tempo do código.
Por exemplo, o Pentium M traz muitas optimizações específicas para as instruções que gerem as pilhas, que são usadas para poupar GPR. Isto continua a ser um problema, is a verdadeira solução é: mais GPR. Mas o aumento de GPR significa uma quebra com o IA32, e consequentemente a definição de uma nova arquitectura. Tanto a Intel como a AMD estão neste caminho. A solução da AMD veio primeiro e chama-se AMD64.
Mais registos
A tecnologia AMD64 consiste num novo modo operativo que comporta duas extensões:
Uma extensão horizontal, que consiste em GPR de 64 bits. Os GPR são ainda uteis como 8, 16 e 32 bits (que permite o K8 ser compativel com programas anteriores), e quando o CPU muda para o modo long mode, o software pode usar os 64 bits na sua totalidade.
O efeitos directos desta extensão são:
O uso nativo de inteiros de 64 bits
O aumento de memória endereçável
Estas melhorias são interessantes, mas a longo prazo, visto não ser uma necessidade urgente.
A segunda extensão fornecida pelo AMD64 consite no aumento do número de GPR de 8 para 16 em long mode. Isto é uma extensão vertical, e a primeira na história do x86. Este aumento facilitará o trabalho do compilador, e diminuirá as instruções de poupança de registos. Por fim, o código será mais pequeno, mais eficiente e mais rápido.
Repare-se que a extensão vertical não tem uma ligação directa com a designação de 64 bits, no entanto é muito mais relevante que a extensão de 64 bits em si. O AMD64 é claro uma extensão de 64 bits dos GPR, mas não é apenas isso.
A par da extensão do GPR, a AMD aumentou o número de registos SSE/SSE2 de 128 bits de 8 para 16, sempre em long mode.
De 32 a 64 bits
Um dos desafios do K8 é introduzir uma nova arquitectura a 64 bits e ao mesmo tempo fornecer uma boa performance com as aplicações a 32 bits. De maneira a conseguir isso, veremos que neste parte a AMD não criou o AMD64 de raiz, mas sim pegando nos padrões da IA32. Isto fez com que o AMD64 seja muito diferente do IA64, porque o legado do IA32 trouxe muitas restrições. Por outro lado, faz com que a transição de 32 para 64 bits seja muito progressiva, o que é necessário para a AMD para impor o K8, e consequentemente o AMD64 aos utilizadores.
Os modos de operação do K8
Basicamente o K8 tem 2 modes de operação: o legacy mode, que faz com que o K8 se comporte com um IA32, e o long mode que é o mode a 64 bits. A tabela seguinte faz um sumário dos modes de operação do K8.

O legacy mode é o modo comum a 32 bits, usado pela maioria dos sistemas operativos. Ao correr neste modo, o K8 comporta-se como um K7. Tem oito GPR de 32 bits, e pode endereçar 4Gb de memória. Graças ao Physical Address Extension, os endereços são extendidos até 52 bits, que permite ao K8 usar 4096Tb, ou 4Pb (Petabytes) de memória virtual.
O long mode é o modo dedicado ao K8. O CPU necessita de ser mudado para long mode pelo sistema operativo, que implica um sistema operativo específico.
O compatibility mode é um sub-modo do long mode, e permite um sistema operativo de 64 bits correr programas de 32 bits. Como é óbvio, estas aplicações continuam a ser aplicações de 32 bits, o que significa que não acederão a registos extra nem memória extra.
De 8 a 16 GPR
Os 16 GPR são um grande melhoramento em comparação à IA32, podemos perguntarmo-nos porquê a AMD não foi mais longe e aumentar o número de GPR ainda mais que 16. Esta escolha reside no legado da IA32, e explicaremos nesta parte como a AMD extendeu a IA32 para criar o AMD64.
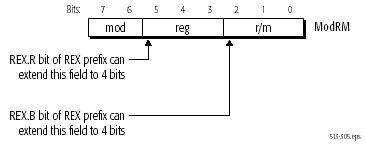
A codificação de instruções da IA32 é feita com um byte especial, na qual são codificadas os registos de origem e de destino da instrução. É o byte MadRM, que significa Mode / Register / Memory. Três bits deste byte são usados para codificar o registo de origem, e três outros para o destino. E três bits permitem codificar 8 valores diferentes, nomeadamente os 8 GPR da IA32.
De maneira a adicionar 8 novos GPR, sem quebrar a compatibilidade com a IA32, é necessário usar 4 bits para codificação de registos, que significa na prática mais um bit. Este bit adicionalestá contido num registo chamado REX, que é dedicado ao long mode, e especifica que a instrução é de 64 bits.
O código a 64 bits
O código de 64 bits consistirá então no uso de 16 GPR para instruções de inteiros e 16 registos de 128 bits para instruções em vírgula flutuante. Uma questão é no entanto levantada quanto ao tamanho do código, que tende a aumentar em comparação ao de 32 bits. Na verdade, instruções de 64 bits usam operandos de 64 bits, que sãoo dobro o tamanho dos de 32 bits. Mais, no caso do AMD64, instruções de 64 bits usam o prefixo REX, que acrescenta mais um byte ao tamanho da instrução. Por fim, instruções SSE/SSE2 também usam um prefixo. Um código maior significa por isso mais tempo para descodificação, e mais uso de cache em comparação com o códigoa a 32 bits.
A AMD no entanto criou uns truques de modo a reduzir o tamanho do código de 64 bits. Por exemplo, suponhamos que queremos escrever 1 num registo, que é escrito em pseudo-código assim:
mov register, 1
No caso de um registo a 32 bits, o valor imediato 1 será codificado em 32 bits :
mov eax, 00000001h
No caso de um registo a 64 bits :
mov rax, 0000000000000001h
Como podemos ver, "1" precisa de 4 bytes em 32 bits e 8 bytes em 64 bits. Incluindo o prefixo REX, isto fará como que as instruções de 64 bits tenham pelo menos mais 5 bytes que as de 32 bits. Isto é um verdadeiro desperdicio de espaço, especialmente porque a necessidade de inteiros de 64 bits é raro na prática. O truque usado pela AMD aparece na tabela:

O tamanho por defeito do operando não será 64 mas 32 bits, e o uso de 64 bits precisará de um bit no registo REX. Assim a instrução vem :
mov rax, 00000001h
A instrução de 64 bits é agora apenas um byte maior que a de 32 bits, devido ao prefixo REX.
Podemos estimar que um código a 64 bits será 20-25 % maior comparado com as mesmas instruções na IA32. No entanto, o uso de 16 GPR tenderá em reduzir o número de instruções, que poderá fazer com que o código a 64 bits fique menor que o de 32 bits. Isto dependerá da complexidade da função, e como é óbvio do compilador.
Aliás, o K8 é capaz de suportar o aumento do tamanho do código, graças às suas 3 unidade de descodificação, e À sua grande cache L1. O uso de grandes blocos de 32Kb na organização da L1 parecem-nos agora muito uteis.
As performances a 64 bits do K8
Plataforma de teste:
|
CPU |
AMD Athlon 64 3400+ (2,2GHz) |
|
Motherboard |
Asus K8V |
|
Memoria |
DDR PC3200 Samsung, 2x512Mo |
|
Placa Gráfica |
ATI Radeon 9600 |
|
Sistema Operativo |
Windows XP
Service Pack 1a |
Compilação de 64 bits
O pre-lançamento do compilador AMD64 causou alguns problemas. O código gerado é completamente seguro, mas o optimizador não está acabado, e algumas optimizações simplesmente não se encontram lá. Por exemplo, o uso de funções trignométricas (senos, cossenos) abrandavam drásticamente o código. De facto, o compilador usa as bibliotecas standard de C para essas funções enquanto que a IA32 as instruções dedicadas de vírgula flutuante. O código destas bibliotecas é tudo menos rápido.
Funções usadas :
Filter : uma função que trabalha em várias tabelas.
Rotozoom : uma função de zoom e rotação, que opera num "buffer" de 512 x 512 x 2 bytes
Arithmetic : funções aritméticas básicas: somas, multiplicações, divisões..
Whetstone: consiste em duas funções similares que misturam operações com vírgula flutuante. Uma usa vírgula flutuante de precisão simples (32 bits), e outra de precisão dupla (64 bits).
Todas estas funções foram compiladas tanto na versão 32 bits como na versão AMD64. Constatamos logo que o código a 64 bits é cerca de 24% maior que a versão a 32 bits. Deu-se um valor arbitrário de 100 aos resultados da versão 32 bits de modo a ser mais visivel a comparação com o AMD64.
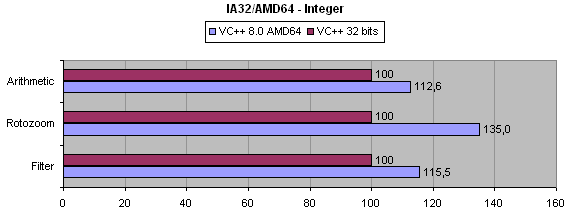
Com um aumento de 35% de performance, a função rotozoom ganha vantagem na compilação a 64 bits.
Código gerado para esta função:
|
32 bits code |
64 bits code |
|
|
|
31 instructions |
23 instructions |
O aumento de performance do AMD64 deve-se à redução do número de instruções em relação aos 32 bits. Como a função usa muitas variáveis, a versão 32 bits faz uso da pilha, enquanto que a versão da AMD consegue armazenar cada variável num registo, usando os 8 registos adicionais (r8 ao r15 no código).
Mas existe outra maneirasde melhorar a performance, e esta aparece nas funções aritméticas. Vejamos um extracto do código:
|
32 bits code |
64 bits code |
|
|
O código de 64 bits continua mais pequeno que o de 32 bits, mas o que é de notar é que o compilador de 64 bits usa a instrução cmovg na linha 10. Esta instrução é uma movimentação condicional e permite evitar um "branch". O compilador de 32 bits não gerou esta instrução mas sim um branch. A instrução cmovg não foi gerada pois esta instrução não está disponível em todos os CPUs (excepto o Pentium Pro).
Aqui encontram-se os resultados obtidos com funções de vírgula flutuante:
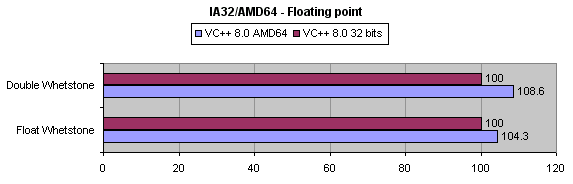
O aumento de performance é baixo em relação aos resultados anteriores. Vejamos o código gerado:
|
32 bits code |
64 bits code |
|
|
O código x87 a 32 bits é um código bastante optimizado e eficiente, e poderá ser difícil melhorar mais ainda. A versão AMD64 usa instruções escalares SSE2("sd" significa "scalar double"). Como podemos verm, o uso destas instruções criam um código que é tão ou mais rápido que o x87, visto o número de instruções ser ligeiramente menor. Enquanto que o x87 gera algumas instruções extra no manuseamento da pilha, o SSE2 acede directamente aos registos.
AMD64 : conclusão
Os resultados obtidos pelo AMD64 são bastante promissores, se considerarmos que é uma nova tecnologia. As versões dos compiladores existentes até agora não são ainda as melhores, e espera-se o lançamento de melhores versões, como foram feitas no caso dos 32 bits. Os resultados são bons mas poderão ainda ser melhores.
A tecnologia a 64 bits é uma aposta, e a AMD corre um grande risco com o AMD64 porque o lançamento da sua tecnologia necessita de "developers" para a usar. Talvez por isso a AMD colocou a sua tecnologia o mais acessivel possível, aproximando os "developers", lançando as documentações do K8/AMD64, etc...tudo para promover o AMD64 entre os programadores. O AMD64 é também muito atractivo para quem o desenvolve, porque o uso dele não necessita de grande trabalho, ao contrário dos SIMD. Isto é um ponto muito importante para o uso do AMD64, visto o seu uso não custar muito e fornece um aumento de performance com apenas uma compilação.
Acerca do K8, este CPU não representa um grande evolução na arquitectura, mas provavelmente nem é necessário. O K8 corrigiu apenas as fraquezas do K7. Melhor performance SSE/SSE2, melhor performance da memória, e uma boa posição no mercado graças à tecnologia HyperTransport.