LightSpeed Memory Architecture II (LMA II)
Na versão anterior da GeForce, foi usada a versão 1 desta tecnologia com a
intenção de eliminar o estrangulamento na largura de banda da memória RAM. Essa
arquitectura foi melhorada e é constituída pelos seguintes 6 segmentos:
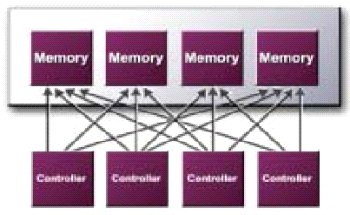
Crossbar Memory Controller
Para além do GPU, outro componente vital no 3D rendering é o controlador de
memória lógico. Devido aos gráficos 3D estarem dependentes da largura de banda
da memória, se esta estiver a ser ineficientemente usada, isto vai dar origem a
engarrafamentos, o que reduz a performance.
O NV25 utiliza 4 controladores de memória. Estes controladores de memória
independentes acedem à RAM, não com blocos de 128bits mas sim com um número
reduzido, de modo a que se possa obter um ganho aproximado de 50% da largura de
banda disponível.
Quad Cache
A LMA-II também tem um subsistema de caches que captura os dados primários, dos
vértices, das textures e dos pixels e envia-os para o NV25 sem necessitar de
aceder à memória.
Lossless Z Compression
Guardando a profundidade das cenas 3D, o buffer Z pode atingir valores na ordem
dos 60fps em alta resolução. A nVidia comprime estes dados a uma taxa de 1:4 em
tempo real, o que reduz a utilização de largura de banda em 1:4.
Z-Occlusion Culling
As arquitecturas gráficas convencionais processam todos os pixels e triangulos
numa cena 3D, o que significa que até os dados que não vão ser mostrados no ecrã
vão ser processados. O que o Z-Occlusion Culling faz é eliminar esses dados
desnecessários. Como resultado, a utilização do GPU e da largura de banda é
menor, podendo assim serem utilizados por outros processos.
Auto Pre-Charge
É um sistema desenhado para reduzir o Miss Penalty de quando o GPU tenta aceder
a uma zona de memória da DRAM inválida.
Fast Z-Clear
Como os dados do buffer-Z ocupavam muito espaço e ele era usado para guardar a
profundidade 3D, era necessário transferir mais rapidamente e comprimir ainda
mais estes dados, pois iria haver um ganho na largura de banda disponível. Um
método de aumentar a performance é de escrever os dados novos por cima dos dados
velhos. Mesmo que nada haja para escrever, a GF4 elimina os dados escrevendo "0"
por cima.