Instruction Set Architecture's
Feito por: Hugo Trovão nº501000909 no âmbito da cadeira Arquitectura de Computadores I
Departamento de Engenharia Informática da Universidade de Coimbra (2005)
| 1. | O que é Instruction Set Architecture. | |
| 2. | Classificação de ISAs. | |
| 2.1. | Arquitectura de acumulador. (Accumulator Architecture) | |
| 2.2. | Arquitectura de stack. (Stack Architecture) | |
| 2.3. | Arquitectura de registos. (Register Set Architecture) | |
| 2.4. | Comparação das várias arquitecturas. | |
| 3. | Número de operandos. | |
| 4. | Memória. | |
| 4.1. | Endereços de memória. | |
| 4.2. | Alinhamento. | |
| 4.3. | Endereçamento de memória. | |
| 5. | Tipos e tamanho dos operandos. | |
| 6. | Arquitectura RISC. | |
| 7. | Pipelining | |
| 8. | Anexo. |
1) O que é Instruction Set Architecture's.
A Instruction Set Architecture (ISA), ou em português Arquitectura de Conjuntos de Instruções, é a parte do processador que é visível ao programador. A ISA serve de fronteira entre o hardware e o software de baixo nível. A ISA de um processador pode ser descrita usando 5 categorias:
De todos os factores referidos, o mais relutante é o primeiro. A ISA porêm, estabelece os padrões de bit's para cada instrução limitando o software a essas instruções, e é complicado a introdução de inovações tendo , por vezes, de se alterar o hardware. Para se evitar essa alteração de alto custo, a ISA deve disponibilizar um conjunto de instruções que permita satisfazer todas as necessidades.
Representação esquemática da interacção de memória, CPU e as entradas/saídas. |

2) Classificação de ISAs.
Como vimos anteriormente, as ISAs podem ser distinguidas por 5 atributos diferentes: localização dos operandos das instruções no CPU, número de operandos chamados por instrução, localização dos operandos da ALU, quais as instruções disponibilizadas pela ISA e por fim pelo tipo e tamanho dos operandos. As ISAs foram mudando e evoluindo com o tempo, adaptando-se às cada vez maiores necessidades de computação.
Como podemos ver, encontramos na evolução das ISAs várias modicações nas arquitecturas. As mais fulcrais foram as de localização dos operandos das instruções no CPU, onde se começou por usar Arquitecturas de Acumulador e se passou a utilizar, a mais actual, Arquitectura de registos. !!!Também existe Arquitectura implementada com Stack, mas acabou por nao singrar!!! Vimos também duas vertentes distinguidas pelo número de operações que disponibilizam, criando o CISC (Complex Instruction Set Computer) e o RISC (Reduced Instruction Set Computer) que são as arquitecturas mais actuais.
|


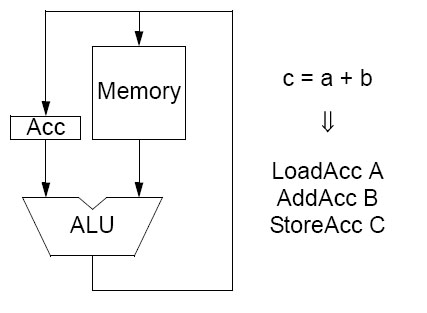
2.1) Arquitectura de acumulador.
A arquitectura de acumulador, como o nome indica, usa um acumulador. Apenas pode usar um operando da memória e o resultado do acumulador para fazer a aritmética, como a figura indica:
|
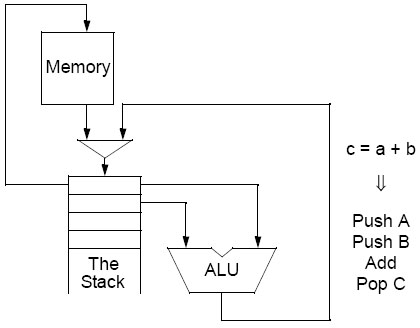
2.2) Arquitectura de stack.
Nota de implementação: A stack está localizada na memória, o CPU apenas contém um registo com um ponteiro para o topo da pilha. Cada instrução causa uma mudança ao ponteiro do topo da stack (TOS) assim como a computação da instrução. |
2.3) Arquitectura de registos.
Na arquitectura de registos existem duas vertentes, uma arquitectura registos-memória e outra, registos-registos. A arquitectura memória-memória já não prospera na nossa realidade.  Os operandos estão explicitamente ou em registo ou em memória. Todas as instruções podem aceder à memória. |
2.4) Comparação das várias arquitecturas.
As arquitecturas de stack e de acumulador foram bastante populares quando apareceram porque a memória era cara, registos eram grandes e caro (queriam-se pouco) e a tecnologia de compilação ainda era primitiva. Os primeiros CPUs eram dos primeios dois tipo mas nos dias de hoje, as arquitecturas de registos dominam. Começou-se a dar menos importância do tamanho do código, os circuitos de alta-velocidade são mais baratos e cada vez mais pequenos, já existe sofisticada tecnologia de compiladores e conclui-se que o uso eficiente dos registos diminui o tráfico de memória, o que atrasa consideravelmente as outras arquitecturas (stack e acumulador). |
3) Número de operandos.
|
4) Memória
4.1) Endereços de memória.
Como são interpretados os endereços de memória? Quase sempre, o endereço é do tipo byte. Embora halfwords, word e por vezes doublewords possam ser acedidas. Existe uma discordância em relação a como são ordenados os bytes numa word em memória e criou-se mais duas vertentes: Big Endian e Little Endian.
|

4.2) Alinhamento.
Na maior parte dos acessos do computador a objectos maiores que um byte têm de estar numa memória alinhada. O acesso a um objecto de tamanho s no endereço A está alinhado se: A módulo s = 0 . A memória está tipicamente alinhada em word ou double word. Acessos não alinhados requerem múltiplos acessos e por isso são mais lentos. Mesmo acesso alinhados, se acederem a um bocado de memória de tamanho inferior ao tamanho do alinhamento de memória, requerem o bitshifting dos dados para a passagem para os registos. |
4.3) Endereçamento de memória.
O modo de endereçamento indica onde se encontra o operando (registo, parte da instrução, ou num endereço de memória). Um cálculo eficaz de endereços é usar o campo de endereço duma instrução para determinar a localização na memória. Os modos mais populares são "displacement addressing mode" e o "immediate/literal addressing mode". O "immediate/literal addressing mode" é usado quando uma constante aparece no código ou um endereço constante é necessário. Assim a maior parte dos valores imediatos requerem menos bits para serem representados. Cerca de um quarto dos loads e das instruções da ALU requerem imediatos. |
5) Tipo e tamanho dos operandos.
Como são os tipos dos operandos designados? Como parte do operando (técnica antiga) ou como parte do campo opcode da instrução (add vs. addf). Existem mais tipos específicos para determinadas tarefas de precisão como números decimais codificados em binário, onde 4 bit's são usados para codificar um dígito decimal. Dois dígitos por byte. Usado em aplicações de negócio onde se pretende ter números decimais exactos. |
6) Arquitectura RISC.
Como vimos, actualmente quase todos os CPUs são de arquitectura de registos (GPR - General Purpose Registers). Alguns exemplos de CPUs são IBM 360, DEC VAX, Intel 80x86 e Motorola 68xx. Sendo estes processadores claramente melhores que os seus anteriores baseados nas outras arquitecturas, eles ainda tinham algumas falhas em certas áreas: as instruções variavam de tamanho de 1 byte a 6-8 bytes. (isto causa problemas com o pre-fetching e pipelining das instruções), as instruções da ALU podiam ter operandos que eram posições de memória (por causa do número de ciclos variáveis que demora o acesso à memória atrasando a instrução). Isto não é bom para os compiladores, pipelining e outras questões. Também, a maioria das instruções da ALU tinham apenas dois operandos e um operando era também o destino do resultado. Isto implica a destruição de um opeando durante a operações ou tem de ser guardado antes noutro lugar.
Nos inícios de 80's a ideia de RISC foi introduzida. Foram iniciados os projectos SPARC, iniciado em Berkley, e o projecto MIPS, iniciado em Standford.
RISC é Reduced Instruction Set Computer. A ISA é composta por instrucções que têm todas exactamente o mesmo tamanho, normalmente 32 bits. Assim as instruções podem ser pre-fetched e o pipelining pode ser usado com sucesso. Todas as instruções da ALU têm 3 operandos, os quais são apenas registos. As únicas instruções que acedem à memóriam são o LOAD e o STORE. Esta arquitectura também é conhecida como arquitectura LOAD/STORE.
|

7) Pipelining.
A ideia de pipeline é da possibilidade de correr várias intruções ao mesmo tempo no processador. Para isso introduziu-se nos processadores o conceito de estágios de computação. Apenas uma instrução de cada vez pode ser executada em cada estágio, mas mal ela acabe o processamento nesse estágio e passe para outro, outra instrução pode começar a ser processada no estágio agora disponível. Isto permite um melhor aproveitamento do processador, levando a desempenhos melhores. Mas nem sempre, todas as instruções podem ser intercaladas nos vários estágios de processamento, podem existir, por exemplo, stall's (paragens) devido a uma instrução estar à espera do resultado de outra instrução anterior, ainda no pipeline. Ou paragens devido a conflitos estruturais (duas intruções quererem usar o mesmo estágio), na qual a última instrução, tem de esperar que a anterior liberte o estágio requerido. Por exemplo, num processador DLX, com 5 estágios principais, Instruction Fetch (buscar à memória a instrução), Instruction Decode (descodificar a instrução), Execute, Memory (manipulação da memória), WriteBack (salvaguarda nos registos), vemos o exemplo:
Se repararmos, na terceira instrução (a adição), existe um R-Stall, uma espera pelas instruções anteriores que fazem o load para os registos dos dados da operação. Depois temos uma instrução de subtracção e acaba o nosso exemplo na trap 0. No entanto, para optimizar ainda mais o uso do processador, usa-se o forwarding dos dados entre estágios. O forwarding consiste em termos vários registos auxiliares em cada estágio e curto-circuitar o circuito de dados podendo multiplexa os dados entre estágios. Mais facilmente será ver o exemplo e comparar com o anterior (a seta verde e' o forwarding dos dados).
Temos as mesmas instruções e menos um ciclo de relógio! O forwarding diminuiu a espera do load dos registos. Os dados passaram do estagio MEM da segunda instrução para o execute da terceira, diminuindo a espera pela escrita para o registo. |


8) Anexo.
Por dentro de um VAX (inglês). Outro uso para uma máquina antiga. Máquinas optimizadas para correr código lisp, LispMachine (inglês). |
htrovao@student.dei.uc.pt